Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue
Paper link: https://arxiv.org/pdf/1603.04992v2.pdf
- single view depth prediction
- unsupervised framework : without requiring pre-training stage or annotated ground-truth depth
- analogous to an autoencoder
Approach
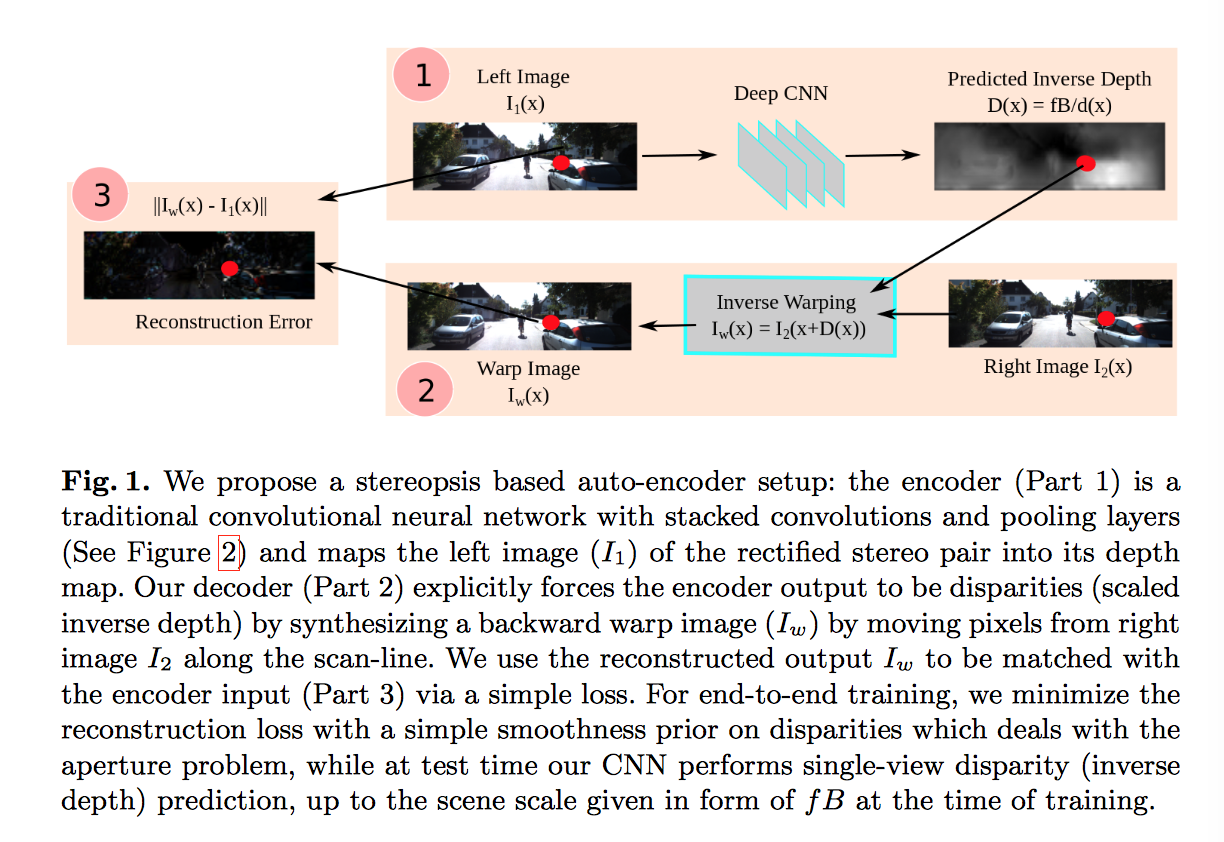
- Make use of pairs of images with a known camera motion, such as stereo pairs.
- CNN: learn the complex non-linear transformation which converts the image to a depth-map
- loss: photometric difference between the input (source image and the inverse warped image) differentiable and highly correlated tieh prediction error
- Interpreted in the context of convolutional autoencoeders
Autoencoder loss
- notation: : Training instance
- notation: : Rectified stereo pair
- notation: : focal length of the two cameras in a single pre-calibrated stereo rig, which capture the image pairs
- notation: : horizontal distance beteen the cameras
- notation: : the predicted depth of a pixel $x$ in the left of the rig
- notation: the motion of the pixel along the scan-line
- notation:
Inline math:
Block math: